Creating PHP Web Sites with Smarty
I recently relaunched SportsFilter using the site's original web design on top of new programming, replacing a ColdFusion site with one written in PHP. The project turned out to be the most difficult web application I've ever worked on. For months, I kept writing PHP code only to throw it all out and start over as it became a ginormous pile of spaghetti.
![]() Back in July, SportsFilter began crashing frequently and neither I nor the hosting service were able to find the cause. I've never been an expert in ColdFusion, Microsoft IIS or Microsoft SQL Server, the platform we chose in 2002 when SportsFilter's founders paid Matt Haughey to develop a sports community weblog inspired by MetaFilter. Haughey puts a phenomenal amount of effort into the user interface of his sites, and web designer Kirk Franklin made a lot of improvements over the years to SportsFilter. Users liked the way the site worked and didn't want to lose that interface. After I cobbled together a site using the same code as the Drudge Retort, SportsFilter's longtime users kept grasping for a delicate way to tell me that my design sucked big rocks.
Back in July, SportsFilter began crashing frequently and neither I nor the hosting service were able to find the cause. I've never been an expert in ColdFusion, Microsoft IIS or Microsoft SQL Server, the platform we chose in 2002 when SportsFilter's founders paid Matt Haughey to develop a sports community weblog inspired by MetaFilter. Haughey puts a phenomenal amount of effort into the user interface of his sites, and web designer Kirk Franklin made a lot of improvements over the years to SportsFilter. Users liked the way the site worked and didn't want to lose that interface. After I cobbled together a site using the same code as the Drudge Retort, SportsFilter's longtime users kept grasping for a delicate way to tell me that my design sucked big rocks.
PHP's a handy language for simple web programming, but when you get into more complex projects or work in a team, it can be difficult to create something that's easy to maintain. The ability to embed PHP code in web pages also makes it hard to hand off pages to web designers who are not programmers.
I thought about switching to Ruby on Rails and bought some books towards that end, but I didn't want to watch SportsFilter regulars drift away while I spent a couple months learning a new programming language and web framework.
During the Festivus holidays, after the family gathered around a pole and aired our grievances, I found a way to recode SportsFilter while retaining the existing design. The Smarty template engine makes it much easier to create a PHP web site that enables programmers and web designers to work together without messing up each other's work.
Smarty works by letting web designers create templates for web pages that contain three things: HTML markup, functions that control how information is displayed, and simple foreach and if-else commands written in Smarty's template language instead of PHP. Here's the template that display SportsFilter's RSS feed:
<?xml version="1.0" encoding="ISO-8859-1"?>
<rss xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:atom="http://www.w3.org/2005/Atom" version="2.0">
<channel>
<title>SportsFilter</title>
<link>http://www.sportsfilter.com/</link>
<description>Sports community weblog with {$member_count} members.</description>
<docs>http://www.rssboard.org/rss-specification</docs>
<atom:link rel="self" href="http://feeds.sportsfilter.com/sportsfilter" type="application/rss+xml" />
{foreach from=$entries item=entry}
<item>
<title>{$entry.title|escape:'html'}</title>
<link>{$entry.permalink}</link>
<description>{$entry.description|escape:'html'}</description>
<pubDate>{$entry.timestamp|date_format:"%a, %d %b %Y %H:%M:%S %z"}</pubDate>
<dc:creator>{$entry.author}</dc:creator>
<comments>{$entry.permalink}#discuss</comments>
<guid isPermaLink="false">tag:sportsfilter.com,2002:weblog.{$entry.dex}</guid>
<category>{$entry.category}</category>
</item>
{/foreach}
</channel>
</rss>
The Smarty code in this template is placed within "{" and "}" brackets. The foreach loop pulls rows of weblog entries from the $entries array, storing each one in an $entry array. Elements of the array are displayed when you reference them in the template -- for example, $entry.author displays the username of the entry's author.
The display of variables can be modified by functions that use the "|" pipe operator. The escape function, used in {$entry.title|escape:'html'}, formats characters to properly encode them for use in an XML format such as RSS. (It's actually formatting them as HTML, but that works for this purpose.)
Because Smarty was developed with web applications in mind, there are a lot of built-in functions that make the task easier. SportsFilter displays dates in a lot of different forms. In my old code, I stored each form of a date in a different variable. Here, I just store a date once as a Unix timestamp value and call Smarty's date_format function to determine how it is displayed.
Smarty makes all session variables, cookies, and the request variables from form submissions available to templates. In SportsFilter, usernames are in $smarty.session.username and submitted comments are in $smarty.request.comment. There also are a few standard variables such as $smarty.now, the current time.
To use Smarty templates, you write a PHP script that stores the variables used by the template and then display the template. Here's the script that displays the RSS feed:
// load libraries
require_once('sportsfilter.php');
$spofi = new SportsFilter();
// load data
$entries = $spofi->get_recent_entries("", 15, "sports,");
$member_count = floor($spofi->get_member_count() / 1000) * 1000;
// make data available to templates
$smarty->assign('spofi', $spofi);
$smarty->assign('entries', $entries);
$smarty->assign('page_title', "SportsFilter");
$smarty->assign('member_count', $member_count);
// display output
header("Content-Type: text/xml; charset=ISO-8859-1");
$smarty->display('rss-source.tpl');
Smarty compiles web page templates into PHP code, so if something doesn't work like you expected, you can look under the hood. There's a lot more I could say about Smarty, but I'm starting to confuse myself.
There are two major chores involved in creating a web application in PHP: displaying content on web pages and reading or writing that content from a database. Smarty makes one of them considerably easier and more fun to program. I'm fighting the urge to rewrite every site I've ever created in PHP to use it. That would probably be overkill.
User-Generated Content Event Offers Super Speaker
There's a User-Generated Content Expo being held in San Jose, Calif., next month. Keynote speakers include Craigslist founder Craig Newmark and CafePress founder Fred Durham.
While browsing the list of speakers to see if they invited any actual content-generating users, I found one of the greatest speaker bios I've ever read. Meet Dawn Clark, founder of DawnClark.Net:
A pioneer in the field of Cyberenergetics, Dawn Clark is a sensitive who stands at the nexus of science and spirituality. Fields influenced by Cyberenergetics include game theory, psychology, biological systems, organizational structure, philosophy, systems theory, and architecture. Dawn's deep insights in energy dynamics at the sub-atomic level are relevant for developing strategic direction and alignment, understanding how products engage, engross and affect subtle fields, all the while factoring in the values of the individuals or audiences critical to making a solution path workable.
Where most people see empty space, Dawn perceives wave form, frequency, and interaction. She sees depth in dimensions and from an early age began experiencing retro and pre-cognitions. A near death experience heightened her sensory abilities. Recognizing her natural gifts, a former elite American counter intelligence agent, whom she assisted in writing books, trained her in the art of spycraft and developed her skills in remote viewing, subtle energy perception and engagement. Rather than apply her skills in the government arena, Dawn chose instead to walk the path of creating solutions, services and learning programs to help people and organizations realize their potential.
Internationally published, Dawn has guided clients working with Fox Entertainment, ABC, PBS, Wall Street Journal Online, 2010 Olympics, and many others, including creative artists, entrepreneurs and researchers. By bringing to light that which is for most unseen, Dawn consults on business development, identifies deep drives of engagement, offers insight as a future historian and tools for empowerment that go beyond what traditional counsel has to offer. A faculty member at the Omega Institute, Dawn is also a member of the Association of Humanistic Psychology, the International Society for the Study of Subtle Energies and Energy Medicine, and the Foundation for Mind Being Research.
I have a theory that every person on earth has one superpower, but it's often such a trivial ability that it goes completely unnoticed. My superpower is the ability to enter any mall department store and know exactly which direction to go when seeking the mall entrance. My power, though occasionally of moderate utility, does not lend itself to a catchy superhero name.
If I could see energy at the sub-atomic level, I'd use that power for a hell of a lot more than helping big media companies reach their potential.
The Sarah Connor's Great-Grandparents Chronicles
David Friedman asks a good question:
Why does Skynet keep sending Terminators after Sarah Connor? Or even John Connor, for that matter? Why not go back a hundred years, or two hundred years, and kill her great grandparents? ...
Future John Connor would surely send a human into the past to stop the Terminator from killing his great great grandparents. So how does this person fight against a robot killer in an age when technology is so primitive, using his knowledge from the future? And how does the Terminator blend in? What materials does he use to repair himself when he's been damaged? Over time, as he gets more and more damaged, does he go from glistening machine to steampunk hodgepodge of parts?
I think there’s a lot of potential for period Terminator stories. Maybe there's an 18th Century Ireland Terminator trying to kill Johnny O'Connor before he comes to America. Or a Dark Ages Terminator who’s trying to kill Sarah the bar wench.
Peace Declared Between Myself and Sweden
As it turns out, Sweden did not intentionally declare war on my web server earlier this month. Programmer Daniel Stenberg explains how the international incident happened:
A few years ago I wrote up silly little perl script (let's call it script.pl) that would fetch a page from a site that returns a "random URL off the internet." I needed a range of URLs for a test program of mine and just making up a thousand or so URLs is tricky. Thus I wrote this script that I would run and allow to get a range of URLs on each invoke and then run it again later and append to the log file. It wasn't a fancy script, but it solved my task.
The script was part of a project I got funded to work on, that was improving libcurl back in 2005/2006 so I thought adding and committing the script to CVS felt only natural and served a good purpose. To allow others to repeat what I did.
His script ended up on a publicly accessible web site that was misconfigured to execute the Perl script instead of displaying the code. So each time a web crawler requested the script, it ran again, making 2.6 million requests on URouLette in two days before it was shut down.
Sternberg's the lead developer of CURL and libcurl, open source software for downloading web documents that I've used for years in my own programming. I think it's cool to have helped the project in a serendipitous, though admittedly server destroying, way.
To make it easier for programmers to scarf up URouLette links without international strife, I've added an RSS feed that contains 1,000 random links, generated once every 10 minutes. There are some character encoding issues with the feed, which I need to address the next time I revise the code that builds URouLette's database.
This does not change how I feel about Bjorn Borg.
Using Treemaps to Visualize Complex Information
I spent some time today digging into treemaps, a way to represent information visually as a series of nested rectangles whose colors are determined by an additional measurement. If that explanation sounds hopelessly obtuse, take a look at a world population treemap created using Honeycomb, enterprise treemapping software developed by the Hive Group:
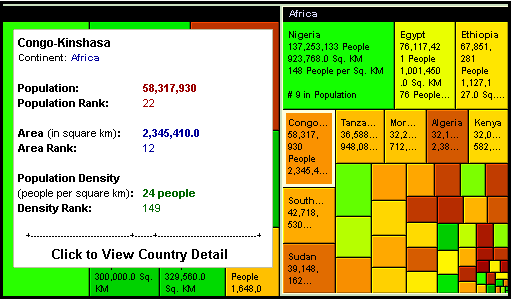
This section of the treemap shows the countries of Africa. The size of each rectangle shows its population relative to the other countries. The color indicates population density, ranging from dark green (most dense) to yellow (average) to dark orange (least dense). Hovering over a rectangle displays more information about it,.
A treemap can be adjusted to make the size and color represent different things, such as geographic area instead of population. You also can zoom in to a section of the map, focusing on a specific continent instead of the entire world. The Honeycomb treemapping software offers additional customization, which comes in handy on a Digg treemap that displays the most popular links on the site organized by section.
By tweaking the Digg treemap, you can see the hottest stories based on the number of Diggs, number of Diggs per minute and number of comments. You also can filter out results by number of Diggs, number of Diggs per minute or the age of the links.
I don't know how hard it is to feed a treemap with data, but it seems like an idea that would be useful across many different types of information. As a web publisher, I'd like to see a treemap that compares the web traffic and RSS readership my sites receive with the ad revenue they generate. The Hive Group also offers sample applications that apply treemaps to the NewsIsFree news aggregator, Amazon.Com products, and iTunes singles. This was not a good day to be a Jonas Brother.
Sweden Declares War on My Web Server
Since 4 a.m. Friday, a computer at a Swedish IT company made more than 1.5 million web requests to my web site URouLette, which links to random web pages stored in a MySQL database. They're coming in at a speed of 38 requests a second. My MySQL database server can't handle that many requests, so by Friday afternoon Workbench and a bunch of other sites slowed to a crawl as the web server began belching black smoke. A massive crash was imminent.
The last time somebody did this, I used the Linux utility iptables to reject all connections from the offending IP address, which solved the problem easy peasy lemon squeezy. This time around, iptables failed with a "Can't open dependencies file" error.
My new friend in Sweden appears to be building a database of web addresses by requesting a URouLette script that loads a random web page over and over. This is both obnoxious and dumb -- all links on URouLette come from the Open Directory Project and can be downloaded in one file. I've reduced the severity of the problem by sending the same link with every request -- the company's home page.
Flooding a web server with this many requests constitutes a denial of service attack. In the time I've composed this blog entry, another 100,000 requests have been made. Ironically, an employee of the company blogged recently that it was suffering its own attack, though on a much larger scale:
Tens of thousands of machines on the internet suddenly started trying to access a single host within the network. The IP they targeted has in fact never been publicly used as long as we've owned it (which is just a bit under two years) and it has never had any public services.
We have no clue whatsoever why someone would do this against us. We don’t have any particular services that anyone would gain anything by killing. We're just very puzzled.
Our "ISP", the guys we buy bandwidth and related services from, said they used up about 1 gigabit/sec worth of bandwidth and with our "mere" 10megabit/sec connection it was of course impossible to offer any services while this was going on.
This is a good time to mention that I never liked Bjorn Borg.
Fixing Page Not Found Errors on FeedBurner MyBrand Domains
Google has begun integrating FeedBurner, the service for publishing, tracking and promoting RSS feeds, into the rest of the Don't Be Evil Empire. As part of the move, FeedBurner users who are employing the MyBrand feature must make a change to the name service for their domain names.
MyBrand makes it possible to host your feeds on FeedBurner without losing any subscribers if you decide later to quit the service. I'm using it to host four feeds, including SportsFilter's RSS feed, on my own domains.
MyBrand domains used to point to feeds.feedburner.com, but they must be changed to a new subdomain of feedproxy.ghs.google.com. Each FeedBurner user is assigned a different subdomain. For SportsFilter, I updated it by revising one line in the BIND zone file for sportsfilter.com:
feeds IN CNAME subdomain.feedproxy.ghs.google.com.
The subdomain portion is based on your Google account.
This is supposed to be all that's required to make the move. Unfortunately, a giant honking bug in FeedBurner broke three of my four MyBrand domains this morning. Users received a 404 "Page Not Found" error when they tried to access my feeds. I found a workaround on Google's FeedBurner help site that explains how to fix the problem:
- Log in to FeedBurner with your Google account.
- Open the MyBrand page.
- Remove the broken domain name and click Save.
- Add the domain name back again and click Save.
![]()
Social Media
![]()
Subscriptions
Blogroll
Projects
RSS Advisory Board
How to Read an RSS Feed with Java Using XOM
The RSS Advisory Board Just Turned 20
Downloading 50,000 Podcast Feeds to Analyze Their RSS
Tara Calishain Explains: What is RSS?
Be Unique And Use RSS Guid Like Everybody Else
Statistics
This blog has been published since Nov. 7, 1999 (a span of 9,626 days).
Thank you for visiting Workbench.
