Et Tu, Rafe Colburn?
Rafe Colburn has an interesting confession regarding the Web nerd cage match we're having over Google Toolbar and other content-manipulation tools:I have a Firefox extension installed called Adblock. All it does is prevent the browser from downloading resources containing the patterns that I specify. I installed it for one reason, to keep my browser from downloading any content from BlogAds.
I make money with BlogAds on two sites, so I could write an impassioned essay about how Colburn is robbing me of a chance to put food on my family. The loss isn't theoretical, unlike Google Toolbar as presently implemented, which I could easily circumvent on book ISBNs.
Although I don't use blockers myself, I've always regarded them as part of the cost of doing business on the Web. People who are strongly motivated to avoid your ads aren't likely to click, so the lack of their eyeballs may be a net good.
I received a certified letter from Blue Cross Blue Shield today straight out of the film Brazil. The contents: one piece of paper cancelling my policy, a 3/4" inch square styrofoam cube, and this note explaining the presence of the cube:Attention
The styrofoam cube enclosed in this envelope is being included by the sender to meet a United States Postal Service regulation. This regulation requires the letter or package to be 3/4 of an inch thick at its thickest point. The cube has no other purpose and may be disposed of upon opening this correspondence.
Prying Into the Google Crowbar
I'm studying the technical implementation of the Google Toolbar to find a JavaScript technique a Web publisher could use to detect and defeat autolinking.I wouldn't use it on Workbench, but if I were Barnes & Noble or another online bookseller, I wouldn't have much patience for software that adds links to my competitors on my pages.
I thought I might be able to compare document.fileSize to the size of the page in document.body.innerHTML.length, but these values don't match and don't change after is pressed.
I found some good and bad things about the implementation.
The good: the current beta enables a user to choose a map provider, which can be Google Maps, MapQuest, or Yahoo Maps. (Click to choose one.)
The bad: You can't use to learn what the Google Toolbar has done to a page after autolinking.
When you try, Internet Explorer shows the source code of the original page. To my knowledge, this is the first time I have ever viewed a Web page where I couldn't examine the exact HTML, JavaScript, and CSS formatting used to create it.
Google Wants to Play Tag
I see it as an issue of 'Who owns the content being displayed?' Google does not own the content, and when it uses the content of others to make money, it often will be violating the intellectual property laws.
-- Attorney Terence Ross on the Google Toolbar's new autolink feature
I can understand the appeal of the argument that anything that exists on your computer is yours to edit, archive, or transform as you see fit. Roger Benningfield sums it up nicely: "My house, my rules."
But we don't seem to be living in that world with our software, and I'd like to see the legal foundation of the belief that we're living there with Web pages and other electronic documents.
Autolink edits Web pages, making subtle inline changes to text while presenting them at their original URLs, which implies the original author created the transformed work.
Even if you accept the legality of these edits, there should be more regard for the notion that something presented under your name is actually your work.
Software that manipulates digital content in transit should not present it as if no changes were made.
Mark Evanier:... many years ago, around the time I started edging into the TV business, I attended a lecture by a very accomplished, successful producer ... a man with many prestigious credits. He told us that we had to recognize and avoid what he called "The Marley Ideas" -- notions so dreadful that they were dead from the moment of conception. As an example, he told us that one TV network was then considering an idea so terrible, so guaranteed to fail, that everyone involved with it should be immediately fired for programming malpractice. And the way he described it, it sure sounded like you'd be an idiot to think that they could make a weekly series out of the movie, M*A*S*H.
Trying the New Google Crowbar
I'm researching the new Google Toolbar beta, which enables Internet Explorer users to click an button that edits Web pages, adding links when it recognizes a book's ISBN number, street address, or package tracking number in the text of a page.Though it's a cool hack, as I said on Jason Levine's weblog, at first glance this seems like overstepping the boundaries of copyright. Robert Scoble voices similar concerns.
I fund my Web server in part through the revenue generated by affiliate links to my books -- sites earned around $3,300 from Amazon.Com referrals in 2004.
In principle, Google Toolbar's new functionality could be used to replace these links with ones that commercially benefit Google.
In practice, the current beta only adds a link to ISBNs that do not already have a link, as you can test on my book list. When the page is loaded, the toolbar's AutoLink button becomes . Clicking the button turns the plaintext ISBN for Movable Type 3 Bible Desktop Edition into a link to Google's toolbar proxy, which in turn redirects to an Amazon page for the book. The ISBNs for other books, which have my Amazon affiliate links, are not altered.
Before:
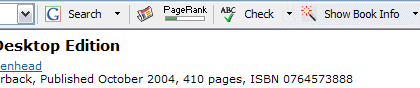
After:
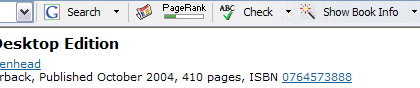
Without question, Google's software is creating a derivative work when a user clicks AutoLink. Levine believes that since a user has the right to alter a work for personal use, provided that it is not redistributed, this feature simply puts that right into practice -- like a TiVo user fast-forwarding past commercials.
I support the use of ad blockers, image blockers, and browser plug-ins that alter the presentation of Web pages for readability or accessibility reasons. Perhaps this falls into the same area.
However, I think this feature is different than software that excludes content entirely or alters it for presentational purposes.
The alterations are so subtle that users would not be clear that a page's publisher did not author these added links, which may be to undesired sites and services.
For instance, if you visit a book's page on the retailer Bookpool, clicking Show Book Info revises the page, linking the ISBN to the book's page on Amazon.Com. Anyone care to guess about whether Bookpool would approve of this change?
Google derives commercial benefit from the added links, and could even implement the feature in a manner that replaces links from which a publisher earns revenue.
This feature reminds me of cases where a company added its own pop-up ads triggered by other publishers' sites or framed someone else's pages.
Carry Google's new feature to its natural conclusion, and a browser such as Mozilla Firefox could add functionality that replaces all affiliate links it recognizes with ones that benefit the Mozilla Foundation.
I have a lot of respect for Levine's armchair legal analysis on Q Daily News -- he's a constitutional law junkie who attended oral arguments in Boy Scouts of America v. Dale and reads amicus briefs for fun. But I have trouble believing the courts would support the for-profit alteration of Web pages in the manner facilitated by the toolbar.
XMLSucks.Org: Well-Formed Criticism
You'd expect a site called XML Sucks to ruthlessly slag the data-description language, but Aaron Crane has produced a pretty even-handed analysis in slides for a LinuxWorld 2003 presentation.XML does have a number of technological problems, but ... the technological problems can be managed [and] the political and commercial advantages of working with the same open standard as everyone else are enormous.
One bogus criticism: Crane's complaint about the verbosity of element names. With today's disk space, processor speed, memory, and compression, it's farcical to think that we need to sacrifice human readability by taking advice like this: "Avoid repeating the element name in the closing bracket."
Somewhere, a coder who had to implement a spreadsheet on a circa-1981 IBM PC in 16K of memory (expandable to 64K!) is reading this and mocking us. And he's saving his work on floppy disks bigger than his head.
{kind=link}
As he notes on his site, Crane originally produced the slides as XML.
![]()
Social Media
![]()
Subscriptions
Blogroll
Projects
RSS Advisory Board
How to Read an RSS Feed with Java Using XOM
The RSS Advisory Board Just Turned 20
Downloading 50,000 Podcast Feeds to Analyze Their RSS
Tara Calishain Explains: What is RSS?
Be Unique And Use RSS Guid Like Everybody Else
Statistics
This blog has been published since Nov. 7, 1999 (a span of 9,633 days).
Thank you for visiting Workbench.
