Wanted: Gluttonous RSS Feeders
Using MySQL and PHP, I'm cobbling together a server-based RSS aggregator/publisher that makes it insanely fast to skim feeds, choosing items for publication without much descriptive text or editing. The code makes use of two terrific open source PHP projects: the Magpie RSS and Atom parser and Edd Dumbill's XML-RPC for PHP.Erik Thauvin uses this approach on Linkblog, checking a mind-boggling 1,600 feeds for technology and programming links and choosing the best 15-20 items each day. His site has quickly become a favorite.
Although I'm not going to adopt this format on Workbench -- I write like someone who gets paid by the word -- when you read Thauvin's description of his editing process, it becomes clear that he's practicing a specialized form of weblogging that could benefit from its own tools.
As I explain this concept to people, I've dubbed this kind of site a passalong, because the point is to scan lots of syndicated feeds and pass along the best links quickly.
For the most part, existing weblogging software is designed under the assumption that users write about everything they link. Radio UserLand can route individual items from the aggregator to an editor, but this wasn't simple enough for the process I have in mind:
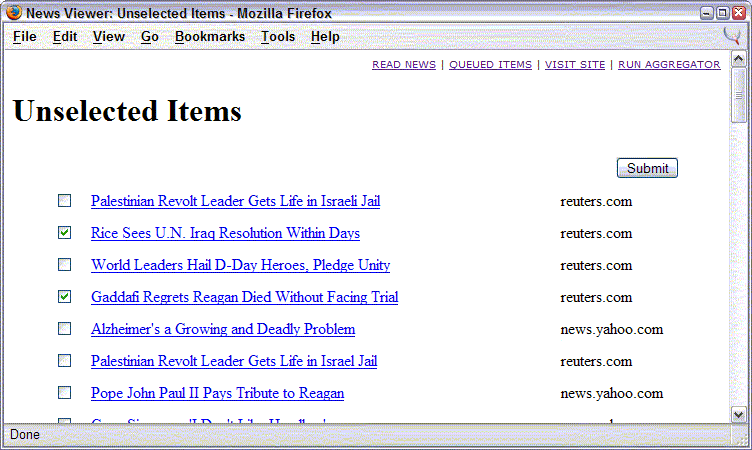
- Scan a headlines page, selecting items that sound interesting. Click Submit to put them all on a queue.
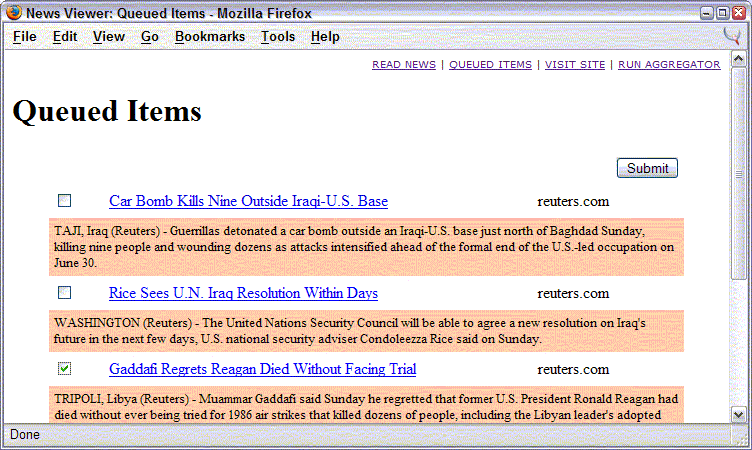
- Skim the queue, which adds item descriptions, and visit links. Select items that should be dropped from the queue, then click Submit to dump them.
- Publish the queue once an hour (in my case, using the MetaWeblog and Movable Type APIs to send items over XML-RPC to a Movable Type weblog).
{kind=link}
{kind=link}
The software needs a lot of work -- there's no editor yet, and I want a Bayesian filter that can guess which new headlines I'm most likely to read -- but I'm jazzed about the potential.
With thousands of information sources producing RSS and Atom feeds, we need people like Thauvin who have integrated weblogging into their daily news-gathering routine. Weblog links are like ant trails -- a lot of people have to link to something good in order to get noticed.
Though my original plan was to design this for personal use, if there's interest, I'll add user account support and make the code available for beta testing. Pass it along.
Comments
Heading in the right direction there Rogers (and Les), imho. I wouldn't be so bothered re. blogging the places myself (though that should be a single gesture) but I do want to be able to actively monitor 10,000+ feeds asap. At present I'm between aggregators (apart from code playthings) because once again I hit that point around 200 or so feeds where it's more effort than it's worth. Roll on the next generation of tools (or the time to handroll one).
You may be able to save yourself some effort by starting out with Feed on Feeds, a PHP/MySQL/Magpie based RSS reader. (it's the feed reader Kellan's re-publishing system is based on) It's not optimized for thousands of feeds, I use it to read hundreds, but it should be pretty easy to change some things around in the templates and get there.
Plus, any changes or extensions you make could get rolled back into the main project.
http://feedonfeeds.com/
I put a couple of screenshots in the numbered list. Here's another way to describe it:
1) Take Radio's aggregator, drop item descriptions, and use the checkbox next to each item to select items for a submission queue.
2) Click one button to put all selected items on the queue.
3) Display the queue just like Radio's aggregator -- item titles, descriptions, and links. Use the checkbox next to each item to select items to remove from the queue.
4) Publish the queue once an hour.
I envision a passalong as the fastest way to route interesting links to the Web. Ideally, it could be incorporated into something the author does anyway.
For instance, my father-in-law keeps up with news about the Caterpillar company via RSS. He could use a passalong to regularly link to items that Cat employees and retirees ought to read.
He doesn't have time to publish a longer weblog, but passing along links collected from RSS is practically effortless.
Rogers -- I ran this tool for a while, which sounds like it has a few things in common with what you're working on, but in the end del.icio.us was a better match for what I was doing.
Rogers:
I'm interested! especially if a module can allow you to opt to drop the link/reference into a database for topical arrangement.
Hmm... got to finish my morning errand. But, I'll send some notes later.
Jim
I have about 1000 feeds. I use them to find articles/postings for my classes. Not necessarily a "classic" blog posting in the line of Doc Searls, but yes, I would be interested in this software.
My thinking is that it's too hard to skim a large number of feeds quickly by reading titles and descriptions. I'd rather scan and select based on heads, then dive in deeper at the next step.
This sounds like exactly what I do for an hour or so every day:
http://www.decafbad.com/links/
I've got a home-brew aggregator in which I monitor 630 feeds. It looks like this:
http://www.decafbad.com/2004/06/dbagg2a.jpg
http://www.decafbad.com/2004/06/dbagg2b.jpg
I've been using a Bayesian-ish filter (spambayes) on unvisited/unrevealed items (spam) and visited/revealed items (non-spam). The results have not yet been all that satisfactory. I'm thinking another sort of classification / filtering algorithm is needed for something where a spectrum of interest level is concerned (versus binary is/is-not spam). Maybe even multiple dimensions - ie. interest and topic.
But anyway, my process for working through feeds goes through a few passes like this:
1) New items: Skim titles, occasionally popping open an item with the disclosure triangle to skim a description. Interesting things get [queue]'d. Hit PgDn a lot.
2) Queued items: Expand all item descriptions, read things a bit more leisurely.
3) Items opened in tabs from the queue. These things I take my time reading, and possibly they get linked.
For the linking itself, I use a combination of del.icio.us and a bookmarklet, and a script that downloads links every few minutes and reposts them to my Movable Type blog.
So a-a-anyway: I'm interested in this sort of thing, so if you need any help or have something you want beaten on, let me know! :)
I've also been experimenting with skimming a large number of feeds and re-publishing a handful of interesting items.
One of the things I found was having to submit all of the items I found interesting in classic webapp style was really slowing me down.
Which is why I'm using Javascript XMLHttpRequest to submit behind the scenes in my reblogging prototype.
http://laughingmeme.org/archives/002117.html
I could kiss you on the lips ... I've been looking and thinking of doing the very same. I've wanted a similar mechanism to help manage and run the 'cache of the day' over at blogs4God.com.
If you need anyone to beta your work, drop me a line. I've already got several blogs in our database with just about every variety of XML/RSS/Atom out there.
Sorry for yet another comment ... but I just noticed the comment above mine mentioned FeedOnFeeds, which is good stuff, but I need something to help me select items over a variety of categories ... having an .OPML for each category. With FeedOnFeeds, you only have the option of a "single set" of feeds.
Okay, in English, I need something where the results of each feed (or .opml) are viewed individually and published their respective categories.
Interested.
Interesting. Is this designed to work as a group (work team) aggregator?
Also: is there a reason not to use the a href "title" feature to embed the description viewable by mouse hover?
Its a very interesting Blog and simple answer of many questions.I think these blog is really useful for new comers and Excellent resource list.
Add a Comment
All comments are moderated before publication. These HTML tags are permitted: <p>, <b>, <i>, <a>, and <blockquote>. This site is protected by reCAPTCHA (for which the Google Privacy Policy and Terms of Service apply).
![]()
Social Media
![]()
Subscriptions
Blogroll
Projects
Statistics
This blog has been published since Nov. 7, 1999 (a span of 9,751 days).
Thank you for visiting Workbench.
