Techmeme: We Find the Sites You Already Visit
Tim Bray on Techmeme:
I go there and see the same stories about the RIAA and Paul Graham's latest essay and what Apple might be doing, the same stories that are on Slashdot and Ars Technica and boring old ZDnet too. Plus a smattering of whatever Scoble & Winer & Arrington & Calcanis and their posses are up to.
For all of the attention paid to the Techmeme leaderboard this week, the latest popularity contest for self-fascinated, high-traffic techbloggers, there hasn't been much scrutiny of the manner in which Gabe Rivera creates his site. Techmeme, which publishes a software-generated roundup of tech news based on links stories receive from favored sources, isn't entirely automated. Rivera begins with a "seed list" of hand-chosen sites, as he explained to Wired News earlier this year:
I do use lists of sources to help my system determine which sources to monitor. Essentially, I'm telling it to "find more sites like these." These aren't exhaustive lists, or even close to exhaustive, and therefore not "white lists." ...
The full set of sites it monitors is constructed automatically, and even changes in real time based on linking. A small "seeding" list I construct manually is used to help the system build the complete list.
Rivera's good at making it sound like an egalitarian discovery process is going on, but Techmeme isn't exactly Lewis and Clark heading off into uncharted territory with a blank piece of paper and a pencil. The site's About page breathlessly declares, "At this moment, the next big story in technology may reside on a blog you've never heard of or a news site you don't have time to scan." Or it may reside on Engadget and TechCrunch, sites discovered 42 times on Techmeme the past week alone.
The Techmeme I want is one that identifies the 100 most-linked sources in technology, then pretends they don't exist. Show me the blogosphere that would exist if Robert Scoble finished journalism school, Mike Arrington remained in the domain name trade, Jason Calacanis became a psychologist and I pursued a career in modern dance.
There's an element of democracy in Technorati rankings and Google pagerank, since they're based on incoming links and the rank of those linkers. TechMeme's leaderboard, on the other hand, is determined by the sites Rivera chooses for his seed list and the stories they link. If he published that list, I expect you'd find the same people and publications who end up on the leaderboard. What goes in one end comes out the other. If you put turkey between two slices of bread, you get a turkey sandwich.
Game Over for Checkers Hall of Fame
Roadside America, a site devoted to the cheesiest tourist attractions in the country, reports the sad news that the International Checker Hall of Fame in Petal, Miss., was destroyed by fire 10 days ago:
On September 29, 2007, a still-unexplained fire started in the tower and quickly engulfed the rest of the Hall. Everything: the giant checkerboards, the library, the statue, was destroyed. "What has been lost is one of the finest checkers collections the world has ever known," said Don Deweber, director of the World of Checkers Museum. "It is almost all irreplaceable."
Mississippi TV station WJTV has video of the house. Curiously, the station touts founder Charles Walker's charitable works without mentioning a word about his checkered past -- he's serving a five-year federal prison sentence for money laundering.
In the TV report, somebody named Scott Waldrop credits checkers legend Marion Tinsley with "some of the first algebraic equations." I have no idea what he means -- algebra has been around for 12 centuries -- but Tinsley was a Florida math professor who had an unbelievable mind for the game. When scientists at the University of Alberta announced that they had solved checkers after 18 years, which means no human can ever beat their software playing the game, they analyzed thousands of moves played by Tinsley and found only a few mistakes. Most of the time, he played the game as perfectly as their proof.
FeedBurner, Uncertainty and Doubt
On Scripting News today, Dave Winer writes that he can't trust FeedBurner:
If things were different I might use Feedburner. Especially on weekday mornings it's amazing how much traffic one file, my RSS 2.0 feed, gets. So it occurs to me that I could streamline things simply by offloading that file to Google. Now that they own Feedburner, this is something I might do, if they take a pledge not to break aggregators that depend on the format of my feed not changing. If someday my feed were to change format and break just one person reading it, I would consider that a serious support issue. It's not something I want to take a chance with. Some people trust me in this way. Not so many people as Google, but to me, they're very important. Could I delegate that trust to Google? No, not at this time.
He's laboring under the misconception that FeedBurner has taken sides in the RSS/Atom war. That's not the case at all. Since the day it was launched, FeedBurner has been Syndication Switzerland. The service won't break aggregators that require a specific format to work properly. In fact, it will even convert feeds from one format to the other dynamically so that they work.
For example, the AmphetaDesk aggregator, one of the earliest desktop feed readers for Windows, doesn't support Atom 1.0. When I tried to add an Atom 1.0 feed to AmphetaDesk, it failed with the error "AmphetaDesk could not determine the format."
I added this feed to FeedBurner, producing a new feed. The feed, when loaded in a browser, is in Atom 1.0 format. But when I subscribe to it in AmphetaDesk, it works without error. A feature called SmartFeed, which is available in FeedBurner's Optimize menu, detected that the request was coming from AmphetaDesk and converted the feed accordingly.
I can understand being cautious about adopting a third-party web service. I tried BlogRush recently and it was a swift and terrible disaster on par with Eddie Murphy's singing career.
But in this case, FeedBurner's painstaking efforts to make feeds work, regardless of which software or feed format are employed by web publishers and readers, are getting lost in the FUD. And that burns me a little.
RSS Best-Practices Profile Up for a Vote
For the last 18 months, the RSS Advisory Board has been drafting a set of best-practice recommendations for RSS. Working with the developers of browsers such as Microsoft Internet Explorer and Mozilla Firefox, aggregators such as Bloglines and Google Reader, and blogging tools including Movable Type, we've looked for areas where questions about the RSS format have led to differences in how software has been implemented to produce and consume RSS feeds.
The result of our work is the RSS Profile. The lead authors are James Holderness, Randy Charles Morin, Geoffrey Sneddon and myself. The profile isn't a set of rules; it's a set of suggestions drafted by programmers and web publishers who've been working with RSS since the format's first release in 1999. Our goal is for the profile to be the second document programmers consult when they're learning how to implement RSS.
The profile tackles some long-standing issues in RSS implementation, including the proper number of enclosures per item, the meaning of the TTL element and the use of HTML markup in character data.
In addition to recommendations for the RSS elements documented in the specification, the profile includes advice for four common namespace elements: atom:link, content:encoded, dc:creator and slash:comments.
Morin and I have proposed that the board endorse and publish the RSS Profile, making it available under a Creative Commons Attribution-ShareAlike 2.0 license so that others can build upon and extend it with their own recommendations.
Additionally, we proposed that the following sentence be added to the About this document section of the specification, as a new fifth paragraph: "The RSS Profile contains a set of recommendations for how to create RSS documents that work best in the wide and diverse audience of client software that supports the format."
Eleven Years as the Dark Humor Man
Exactly 4,200 days ago, I began Cruel Site of the Day, a demented parody of Cool Site of the Day and other award sites. I had just left an interactive TV startup in Denver that went broke the day our product launched and was starting my own web development company in Pekin, Illinois, a town outside of Peoria where the air smells like corn, marigolds and hopelessness.
![]()
As Wall Street was making overnight dot-com millionaires out of a bunch of insufferably precocious twentysomethings like Marc Andreesen, I was a new parent struggling to become a ten-thousandaire. Peoria has its charms, like the Giant Bikini Woman, the gondola sandwich and the first mass production of penicillin. But Illinois is Fargo-the-movie cold, and as it turned out, the Rust Belt wasn't the best place to become an Internet mogul.
So on April 1, 1996, it was easy to channel my resentment into a site that mocked the chirpy optimism of people like Glenn Davis, the creator of Cool Site of the Day, who was constantly in the press saying things like this:
I view the Web as I view life, with the sense of wonder of the little boy that I carry inside of me. When he says, 'that's cool,' I listen.
Somebody needed to make the case for the other side:
The World Wide Web is a great thing, putting a wealth of sports information, entertainment trivia and explicit pornography at your fingertips. ... However, there's something wrong with a medium that loves itself as much as the Web does. We're being turned into a planet of Steven Seagals. As an antidote to all of this unhealthy positive energy, Cruel Site of the Day presents a daily link to the world of the perturbed, peeved, pensive and postal. It's brought to you by Rogers Cadenhead, a web developer who began examining the issue of self-love in his early teens.
{kind=link}
Today, thousands of people bottomfeed the web to amuse, anger and appall an audience, led by Fark and Something Awful. Even Glenn Davis was lured to the dark side. After Cool Site of the Day was taken away from Davis and his second venture, the web development community Project Cool, was bought and imploded by JupiterMedia, Davis told the New York Times in 2002 that he had quit using the web entirely and had "lost our sense of wonder."
You can probably see where this is going. I'm announcing my retirement from the dark humor and wacky Internet link business. Cruel.Com will be adopting a new format on Nov. 1 that's not powered by bile and can be visited without peril to your immortal soul. The site has grown into a 3,750-member community of users who have posted thousands of links and comments, and I'd like to see that continue under a new web publisher if a deal can be worked out. I even have an unused domain that's well-suited to the purpose: ridicule.net.
But for me, I'm making my last cruel site the one that convinced me the project was worth doing, a few weeks after the launch when traffic was non-existent. The David Spade Escapade, archived on my server with the permission of the author, explains why Spade will never be welcome in the state of Montana.
Randy Charles Morin and I are going to propose the RSS Profile to a vote of the RSS Advisory Board next Monday. The effort to draft a set of best practice guidelines for RSS 2.0 has been 18 months in the making. If you see any issues that should be addressed before the vote, or there are changes you'd like us to consider, let us know on the RSS-Public mailing list.
BlogRush Offers Link Sharing Service for Blogs
As an experiment, I added a BlogRush widget to the sidebar of Workbench and several other sites this morning. BlogRush is a new JavaScript-based blog headline exchange driven by RSS. Here's how it works: Headlines that might be of interest to readers appear in a box like this one, headlines from my site appear on other member sites, and we all get an enormous boost in traffic, a slobbery cover story in Wired and obscene wealth we can lord over others. Or at least the BlogRush founders do.
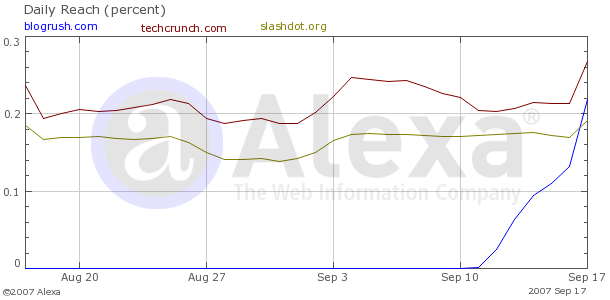
 BlogRush is viral -- your headlines appear more often based on how many hits, clicks and member referrals you attract. The site's just six days old, but the marketing gimmick's bringing the Orlando-based startup a ginormous amount of traffic. On Alexa, BlogRush has passed Slashdot and is threatening TechCrunch.
BlogRush is viral -- your headlines appear more often based on how many hits, clicks and member referrals you attract. The site's just six days old, but the marketing gimmick's bringing the Orlando-based startup a ginormous amount of traffic. On Alexa, BlogRush has passed Slashdot and is threatening TechCrunch.
{kind=link}
The BlogRush widget only displays the first 40 characters of a headline, including spaces, so a lot of the headlines it displays are cut off or misleading. Although the service suggests that you write headlines with this limit in mind, that's too much to ask. A better solution would be to create a BlogRush namespace for RSS, so publishers who wanted to write shorter headlines for the service could define them in their RSS feeds, like this:
<item>
<title>'Kid Nation' Contestants Rip Into President Bush</title>
<blogrush:title>'Kid Nation' Stars Rip President Bush</blogrush:title>
</item>
I've never found a widget I wanted to keep around for long, because their providers always have trouble ramping up servers fast enough to avoid slowing down the sites that belong to the networks. But some of the headlines BlogRush has found for the Drudge Retort widget have been interesting, which is either dumb luck or good context-based filtering. I'll follow up this post in a week or two with details on how much traffic BlogRush generated for my sites.
![]()
Social Media
![]()
Subscriptions
Blogroll
Projects
RSS Advisory Board
How to Read an RSS Feed with Java Using XOM
The RSS Advisory Board Just Turned 20
Downloading 50,000 Podcast Feeds to Analyze Their RSS
Tara Calishain Explains: What is RSS?
Be Unique And Use RSS Guid Like Everybody Else
Statistics
This blog has been published since Nov. 7, 1999 (a span of 9,745 days).
Thank you for visiting Workbench.
